这次的paper是关于Fact Extraction and Verification的,跟之前在做的Stance Detection有点类似吧,二者好像都在Fake news这个大任务里。前两篇论文笔记介绍了Stance Detection的几篇paper,这篇论文笔记我们来简单谈一谈Fact Extraction and Verification(事实抽取和证实)。由于我也是刚接触这个任务,所以有错误的地方还望指正。
[NAACL’18] FEVER: a large-scale dataset for Fact Extraction and VERification
这篇论文主要是提出了一个大规模的数据集用于事实抽取和证实任务,并提出了一个基本的Pipeline方法用于解决这个任务。
Introduction:
首先介绍一下Fact Extraction and VERification (claim verification)任务,见图1。给定一个claim,首先从文档中抽取出能够证实/证伪该claim的证据(evidence)句子,然后根据抽取出的句子判断这些证据对该claim是支持/ 反对/ 不充分的(supported/ refuted/ not enough info)。例如图1中,Claim为”The Rodney King riots took place in the most populous county in the USA.”,根据两个证据句 (1) “The 1992 Los Angeles riots, also known as the Rodney King riots were a series of riots, lootings, arsons, and civil disturbances that occurred in Los Angeles County, California in April and May 1992.” (2) “Los Angeles County, officially the County of Los Angeles, is the most populous county in the USA.” 可以判断出他们支持(Supported)该Claim的论述。

Comparison:
本文将FEVER与Textual Entailment (TE)/ Natural Language Inference (NLI)文本蕴含任务以及Question Answering (QA)问答任务进行了比较(关于这两个任务的介绍我放在附录吧,见文末)。与通常只有根据一条固定的文本句来判断是否蕴含的NLI任务相比,FEVER的evidence提取自大量的文档;在QA任务中,问题中通常隐含提供了确定答案的信息,而对于一个claim而言,其缺失的信息通常对于检索反驳证据至关重要。例如Claim: “Fiji’s largest island is Kauai.”可以被检索出的该证据: “Kauai is the oldest Hawaiian Island.” 反驳(即Kauai其实是Hawaiian一个岛,而不是Fiji的),而该Claim中根本没有提到过Hawaiian,即Claim中缺失了这个信息。我的理解的话,是不是可以这样想,对于QA任务,Answer是不会去反驳质疑Question的正确性,而一定会顺着Question找到一个“答案”。
Motivation & Dataset:
作者提出,目前NLI和QA任务都有大规模的数据集供大家研究,但claim verification的数据集相比之下规模却很小(仅几百个claim)。因此,本文提出了一个包含185,445条claim的数据集。数据集的标注构造分为两个阶段:第一阶段,从Wikipedia中抽取claim句子并用各种方式改写他们,其中有可能改变原意;第二阶段,根据claim在文章pages中抽取出evidence,文章中不包括改写该claim时对应的原句。这样构建出的数据集,对于31.75%的claim有不止一个evidence句可以被认为是适当的,16.82%的claim需要多个句子作为evidence进行组合,12.15%的claim其evidence来自多个pages。
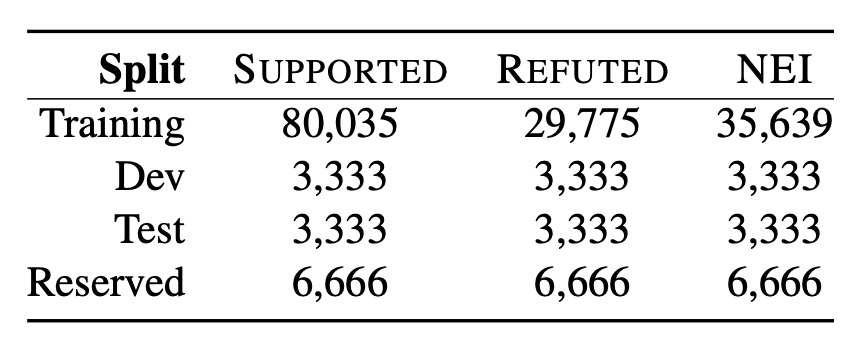
数据集的划分如图2。所有claim所产生的那个Wikipedia的page都包含在其同一个set下,也就是说不会出现某个set里的claim在本set中找不到其被改写原句所在的page的情况。
Method:
针对FEVER任务,该paper还提出了一个Pipeline的解决方案:给定一个Claim,首先根据Claim识别出相关的文章,从这些文章中选择句子组成evidence证据,根据选择的证据句,对Claim进行分类。该Pipeline可以分为三个模块:Document Retrieval,Sentence Selection和Textual Entailment。
Document Retrieval: 利用TF-IDF算法计算出文章的词频向量,并计算与原Claim的余弦相似度,找出k个最相似的文章。
Sentence Selection:同样是利用TF-IDF相似度找出文章中与Claim相似的句子并按照相似度进行排序,利用验证集的结果来调整选取最相似的句子(相当于调参的过程,到底选前多少条最相似的句子作为evidence是通过验证集选出来的)。同时,为了评估Sentence Selection对最后结果的影响,作者还做了省略这一步直接Document Retrieval后做Textual Entailment的实验。
Textual Entailment:一个简单的baseline是2017 Fake News Challenge一个队伍的做法 ,将evidence和claim的词频TF-IDF余弦相似度输入到有一层隐藏层的MLP得到;另一个比较SOTA的方式是在evidence和claim之间用decomposable attention (DA) model ,是当时斯坦福的NLI任务评测中有公开代码的最高分数模型,同时这个模型不需要对文本进行语法分析,也没有用集成结果。对于not enough info这一类而言,没有对应的evidence的golden label,因此无法使用上面两个方法训练,所以作者模拟了这一类的训练数据,通过从最相似的文章中sample一个句子或者随机地从Wikipedia中sample的句子组成。
Experiments:
这篇paper做了好几个实验,关于pipeline前两个模块提取evidence的upper bound结果(即只要evidence提取正确就默认后面claim分类是正确的),衡量前两个模块对最终结果的影响等。之后的工作中好像更多地提到的是,是否考虑模型提取出的evidence的正确性,还是只考虑最后三分类结果的准确率。如果同时要求模型提取出的evidence和最后三分类的结果都正确的话,得到的acc为31.87%;如果忽略evidence是否正确,则三分类的acc可以达到50.91%。说明在某些情况下,虽然模型能够成功地判断claim是否正确,但是它所依据的evidence其实跟人类标注的不一样,模型在测试集上前两个模块中找evidence的F1才17.47%。
附录:
Textual Entailment (TE) / Natural Language Inference (NLI)文本蕴含:文本蕴含关系描述的是两个文本之间的推理关系,其中一个文本作为前提(premise),另一个文本作为假设(hypothesis),如果根据前提P能够推理得出假设H,那么就说P蕴含H。而该任务主要目标是对前提和假设进行判断,判断其是否具有蕴含关系(entailment,contradiction,neutral),即作为一个文本分类任务。
Question Answering (QA)问答:分为基于知识图谱,基于阅读理解两种QA。事实性的QA任务从知识图谱中寻找问题的答案;而基于阅读理解的QA任务会从非结构化的文章中获取答案,本文所提到的这篇paper 应该主要是与这个任务进行了比较。基于阅读理解的QA任务可以分成匹配式QA,抽取式QA和生成式QA:匹配式QA是给定文章,问题,和一个候选答案集(一般是实体或者单词),从候选答案中选一个score最高的作为答案;抽取式QA是给定一篇文章,围绕这篇文章提出一些问题,然后从文章中抽取出答案;生成式QA中的答案可能出现在某篇文章/多篇文章,或者没在所有文章中出现,由原文/ 原文+问题/ 原文+新词等形式生成。
(题外话:大家都好会取名字啊,怎么都要硬凑一个单词缩写出来e.g. FEVER, BERT, etc.)
Reference
- GEAR: Graph-based Evidence Aggregating and Reasoning for Fact Verification https://www.aclweb.org/anthology/P19-1085
- FEVER: a large-scale dataset for Fact Extraction and VERification http://aclweb.org/anthology/N18-1074
- A simple but tough-to-beat baseline for the Fake News Chal- lenge stance detection task. https://arxiv.org/abs/1707.03264
- A decomposable attention model for natural language inference. https://aclweb.org/anthology/D16-
- 自然语言推理-文本蕴含识别简介 https://blog.csdn.net/u010960155/article/details/81335067
- 问答系统总结(Question Answering System, QA) https://www.cnblogs.com/baobaotql/p/13820871.html